В любом проекте человеческий фактор никто не отменял, и если пользователи самостоятельно
грузят картинки на сайт — появления дубликатов не избежать. Когда доходит до тысяч файлов, глазами всего не пересмотреть, а повторяющиеся картинки мало того, что никому не нужны, так еще и занимают место, тратят ресурс и в конце концов тормозят работу.

Потому рано или поздно встает вопрос автоматизации процесса поиска повторов, и тут мы рассмотрим основные, а также попробуем в деле.
Сравнение файлов через функцию hash
Одним из способов определения дубликатов является сравнение файлов путем генерации хеш-значения из содержимого заданного файла.
Простой пример вычисления хеша изображения:
<?php
imagecreatefrompng('image.png');
echo hash_file('md5', 'image.png');
?>
Результат выглядит примерно так: bff8b4bc8b5c1c1d5b3211dfb21d1e76
Если хеши двух изображений совпадают — изображения одинаковые.
Метод далеко не самый точный, так как работает только для идентичных картинок, при малейшем различии — толку ноль.
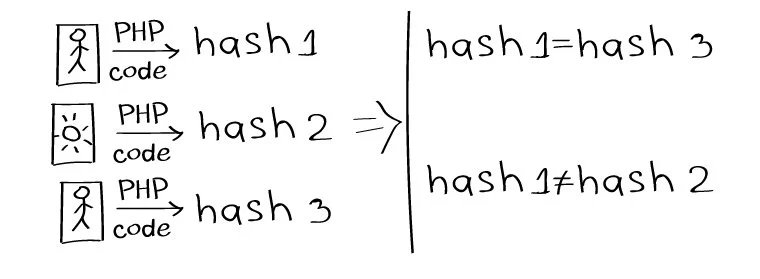
ImageMagick
Функция обработки изображений Imagick::compareImages возвращает массив, который содержит восстановленное изображение и разницу между изображениями.
Пример использования при сравнении двух изображений:
<?php
header("Content-Type: image/png");
$image1 = new imagick("image1.png");
$image2 = new imagick("image2.png");
$result = $image1->compareImages($image2, Imagick::METRIC_MEANSQUAREERROR);
$result[0]->setImageFormat("png");
echo $result[0];
?>
В итоге две сравниваемые картинки лепятся в одну, на которой видны отличия.
Также можно получить числовое выражение отличий по каждому параметру (пример с
оф.сайта):
-> compare -verbose -metric mae rose.jpg reconstruct.jpg difference.png
Image: rose.jpg
Channel distortion: MAE
red: 2282.91 (0.034835)
green: 1853.99 (0.0282901)
blue: 2008.67 (0.0306503)
all: 1536.39 (0.0234439)
gd2 и libpuzzle
Для быстрого поиска дубликатов необходимо установить библиотеки
gd2 и
libpuzzle.
Установка:
apt-get install libpuzzle-php php5-gd
Libpuzzle создана для быстрого поиска визуального сходства изображений (
GIF,
PNG,
JPEG). Сначала растровая картинка разбивается на блоки — автоматически отбрасываются рамки, не несущие особо значимой информации. Разница между смежными блоками формирует вектор — это так называемая подпись картинки. Похожесть картинок определяется расстоянием между двумя такими векторами. Потому обычно изменение цвета, ресайз или сжатие не влияют на результаты, выдаваемые libpuzzle.

Libpuzzle довольно проста в использовании. Вычисление подписи для двух изображений:
$cvec1 = puzzle_fill_cvec_from_file('img1.jpg');
$cvec2 = puzzle_fill_cvec_from_file('img2.jpg');
Вычисление расстояния между подписями:
$d = puzzle_vector_normalized_distance($cvec1, $cvec2);
Проверка изображений на схожесть:
if ($d < PUZZLE_CVEC_SIMILARITY_LOWER_THRESHOLD) {
echo "Pictures are looking similar\n";
} else {
echo "Pictures are different, distance=$d\n";
}
Сжатие подписей для хранения в базе данных:
$compress_cvec1 = puzzle_compress_cvec($cvec1);
$compress_cvec2 = puzzle_compress_cvec($cvec2);
Перцептивный хеш
Вероятнее всего, самый точный способ нахождения дубликатов — сравнение файлов через
перцептивный хеш. Проверка на схожесть проводится путем подсчета количества отличающихся позиций между двумя хешами, это
расстояние Хэмминга. Чем расстояние меньше — тем больше совпадение.

Отличается от первого способа тем, что указывает не только на одинаковость/неодинаковость, но и на степень различия. Подробнее об этом принципе можно прочитать в
неплохом переводе.
Установка для UNIX платформ выглядит так:
$ ./phpize
$ ./configure [--with-pHash=…]
$ make
$ make test
$ [sudo] make install
Попробовать на деле можно через
i.onthe.io/phash. Загрузка изображений через интерфейс и на выходе показатель «одинаковости».
Как это работает
Получаем хеш первого изображения:
$phash1 = ph_dct_imagehash($file1);
Получаем хеш второго изображения:
$phash2 = ph_dct_imagehash($file2);
Получаем расстояние Хэмминга между двумя изображениями:
$dist = ph_image_dist($phash1,$phash2);
Мы проделали почти все возможные манипуляции с одной и той же фотографией, чтобы проверить — какие изменения мешают определять дубликаты через pHash, а какие — нет.
Например, при зеркальном отражении — картинка
остается неузнанной.
Зато с цветами можно играться сколько угодно — на
результат сравнения это не повлияет.
Чего нельзя сказать о манипуляциях с RGB-каналами, Джона
опять не узнали, хоть и расстояние Хэмминга для такого случая гораздо меньше.
Остальные результаты выглядят так:
| Не мешают (расстояние Хэмминга = 0) | Мешают (расстояние Хэмминга — в скобках) |
|---|
| Измененное имя файла |
Кроп (34)* |
| Формат (JPEG, PNG, GIF) |
Поворот 90° (32)** |
| Оптимизация Google PageSpeed |
Зеркальное отражение (36) |
| Ресайз с сохранением пропорций и без |
Изменение положения кривых в RGB-каналах (18) |
| Изменение цветовой гаммы и четкости |
|
*зависит от величины кропнутой области. При отрезании от картинки маленькой рамки толщиной в несколько пикселей, расстояние Хэмминга будет нулевым, следовательно сходство — 100%. Но чем ощутимее кроп — тем больше расстояние — тем меньше шансов обнаружить дубликат. О поиске кропнутых дубликатов через перцептивные хеши можно почитать
тут.
**то же самое, что и с кропом. При повороте на пару градусов расстояние незначительное, но чем больше угол наклона — тем сильнее различие.
Конспект
- Для сравнения картинок используйте ImageMagick, а для поиска полностью идентичных — сравнение через хеш.
- Чтобы находить незначительно измененные изображения — используйте библиотеку libpuzzle.
- Сравнение через перцептивный хеш — одно из самых надежных, можно попробовать тут.
